
Turning Audio Recordings into Conservation Action: A Scalable AI Workflow for Biodiversity Monitoring
How we’re using open data, AI models, and cloud infrastructure to help communities detect and monitor species faster, cheaper, and at scale
Across the world, passive acoustic recorders are capturing the sounds of wildlife, from tropical frogs to elusive forest birds. Collecting audio is only the beginning though. For most conservation groups, the real challenge comes next:
How do you transform millions of minutes of recordings into useful, trustworthy biodiversity data, without costly infrastructure, time-consuming manual processing, or heavy dependence on data scientists and coding experts to run complex analyses?
At WildMon, we’ve spent the last year developing a scalable, cloud-ready workflow to solve this problem. Built for modularity and grounded in real-world field constraints, the system combines pre-trained AI models, open biodiversity data, and smart and intuitive validation tools to support acoustic monitoring across diverse ecosystems.
We’ve applied this workflow across 14 projects in 10 countries, processing over 10 million minutes of audio, detecting hundreds of species, including birds, mammals, amphibians, and insects, and helping local teams answer critical ecological questions.
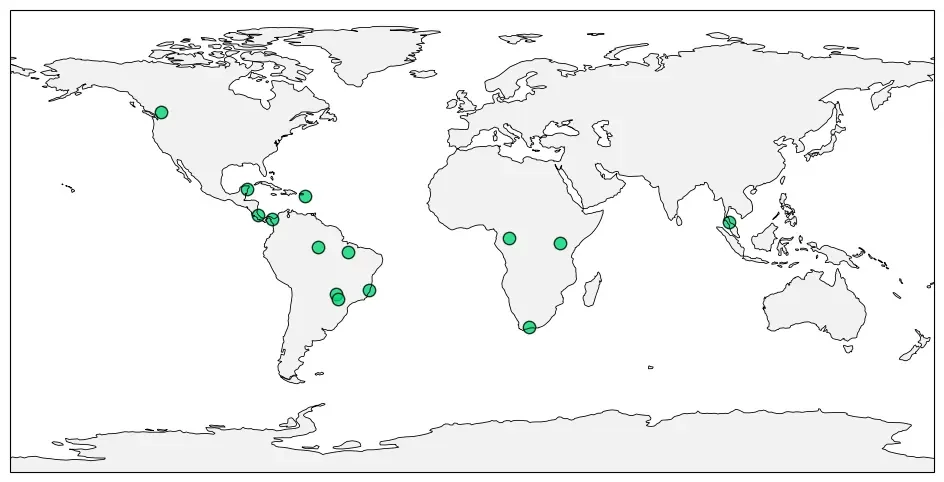
Real-world applications of our scalable workflow, deployed in 14 biodiversity monitoring projects across the Americas, Africa, and Asia.
Now, we’re preparing to turn this workflow into an open-source platform that communities around the world can use, without coding expertise required, to monitor biodiversity where it matters most.
A Shared, Scalable Framework for Acoustic Monitoring
Our goal was to create a system that’s:
Accessible — so that even non-technical teams can use it.
Efficient — powered by embeddings (compact numerical representations of sound that make audio easy to analyze) and parallel cloud computing to cut costs and speed up results.
Modular — compatible with multiple AI models and components, allowing future sustainability as technology advances.
Collaborative — built so teams around the world can work together, validate detections, and improve the system.
Community-driven—Improves over time as people add new species, data, and models that are open to everyone.
At the heart of the workflow is a simple but powerful idea:
→ Extract audio embeddings once, and use them to drive everything else: classification, search, model training, and analysis.
Here’s how the workflow works in practice:
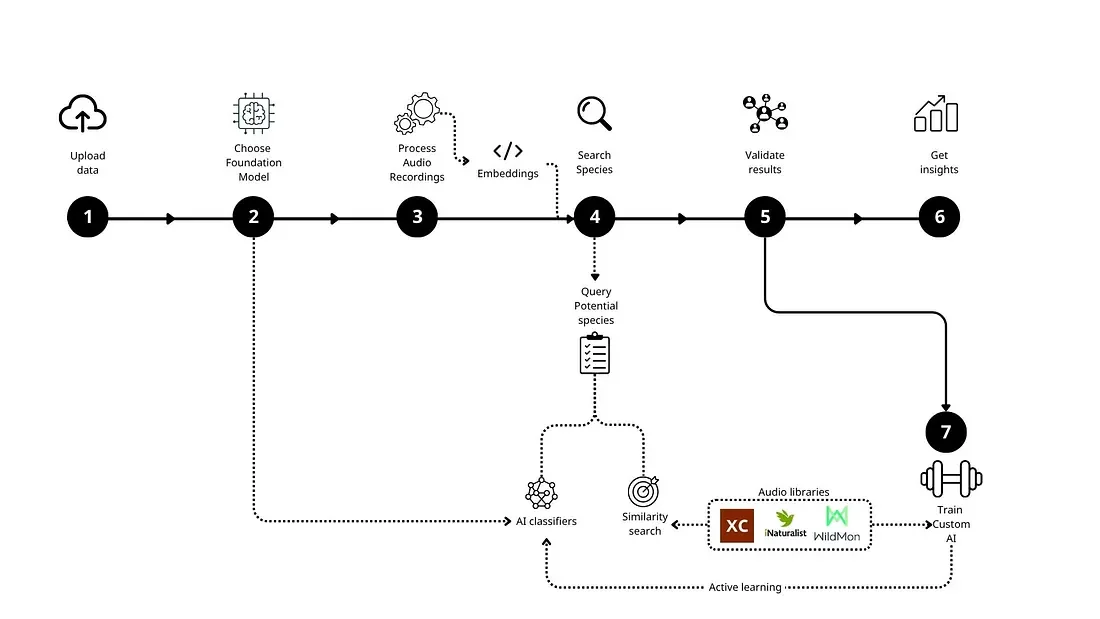
Workflow overview for scalable acoustic biodiversity monitoring, from data upload to insights.
①–③ Process and Embed Audio
Recordings are uploaded into Google Cloud Storage, segmented, and passed through a pre-trained foundation model like BirdNET, Perch, or BirdSET, to generate embeddings — compact, reusable numerical representations of sound. This step is the most computationally intensive, but it only happens once per dataset.
We use a parallelized cloud infrastructure in Google Cloud to distribute the workload. We also compute acoustic indices for ecological analysis. Everything is saved in compressed format for fast access downstream.
④ Search Species
Generate a Local Species List
Using the recording coordinates, we query biodiversity occurrences databases like GBIF to generate a tailored list of species expected in the area. This helps focus downstream analysis by:
Filtering classifier model results to only show geographically relevant species
Identifying rare or overlooked species not covered by current models, especially frogs, insects, and mammals that are missing in the bird-focused foundations models
Searching open audio repositories like Xeno-Canto and iNaturalist, for example, for reference calls of those missing species to power embeddings similarity search
This component can easily evolve to a more comprehensive and model-based species list, such as the new AI-based geospatial tools from iNaturalist GeoModel, to further improve accuracy in under-sampled regions.
Detect Species Using AI Models and Embedding Search
Once we have the embeddings and species list, we detect vocal species using two approaches:
AI classifiers (e.g., original BirdNET or lightweight custom/regional models based on the chosen foundation model) can quickly recognize the “bulk” of species with high performance. They’re especially effective for the most common species, and custom versions can boost performance for local contexts or expand coverage to other species if enough training data are available.
Embeddings similarity search works like a “find similar sounds” tool. We take one or more reference calls of a species (say, a frog call from Xeno-Canto) and compare their embeddings to all the embeddings in our dataset. Using a similarity measure (cosine distance), we can flag recordings that closely match. This lets us detect rare, local, or understudied species that aren’t included in the existing classifiers.
This dual approach allows us to cover a wider range of taxa, including rare or local species not present in foundation models. Searches are fast and efficient, since they operate on pre-computed embeddings, not raw audio, allowing fast iterations.
⑤ Validate What Matters, Not Everything
Our web-based validation tool makes it easy to review detections. Each record comes with an audio snippet, spectrogram, and example calls from the species, making it intuitive even for non-experts to contribute.
But what really saves time is how the tool helps you focus only on what matters. Instead of reviewing thousands of detections, smart filters guide the process based on your ecological goal:
Want a quick species list? Just check the top result per species.
Doing trend or spatial modeling? Focus on one of the top detections per site per day.
Building a custom classifier? Sample across high and low confidence scores for iterative active learning modeling.
This means you validate just what you need, not everything. It’s a flexible, human-in-the-loop, efficient system to turn raw AI results into reliable biodiversity data, with minimal effort and maximum impact.
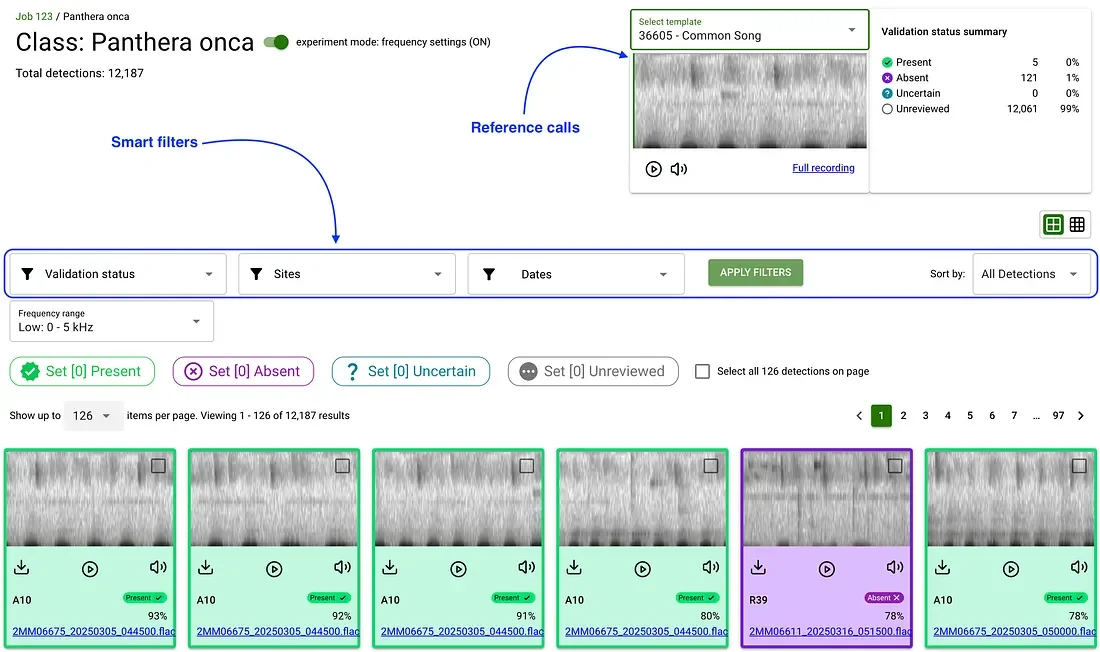
A human-in-the-loop interface for validating AI-generated detections, using reference calls for support and filters to prioritize effort — here showing a jaguar calling in the forests of Guyana.
⑥ Exporting Results and Generating Ecological Insights
Once detections are validated, they can be exported in multiple formats, ready for ecological analysis, reporting, and sharing. Outputs include:
Species lists and site-level summaries for inventories and quick assessments
Detection-level tables for modeling presence, activity patterns, or trends
Darwin Core (DwC) Standard, a format used to publish species records to GBIF and also integrated into WildMon’s dashboards, making it easy to share validated data with global databases and local partners alike.
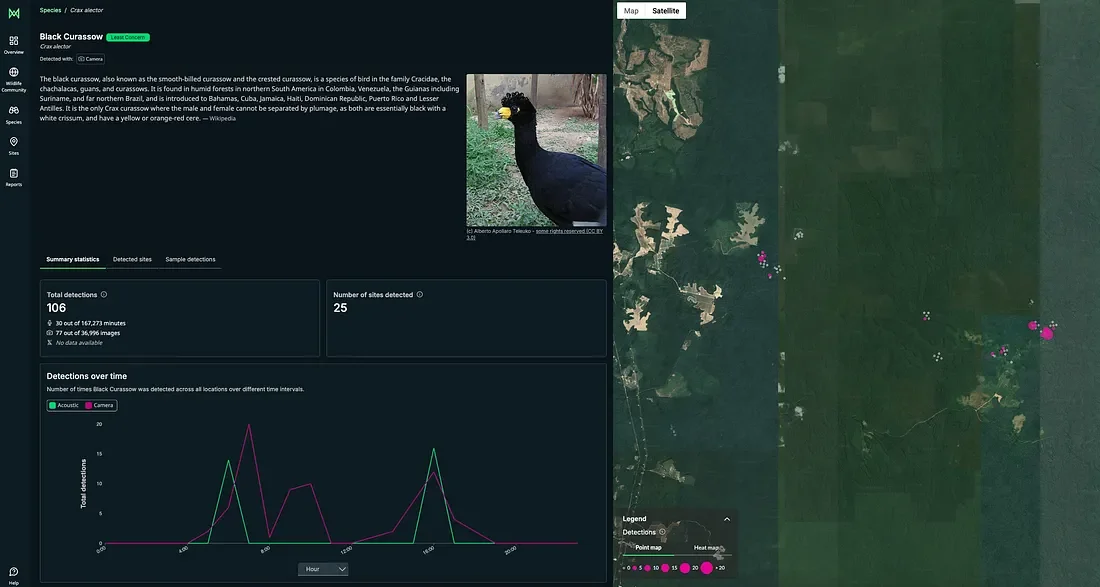
Exported results can be visualized in an interactive dashboard to gain quick ecological insights.
⑦ Build Smarter Models as You Validate
And here’s where it gets powerful: Users can leverage their validated data to train and reapply lightweight custom classifiers directly on the embeddings, dramatically improving results over time. These models are fast to deploy, don’t require deep learning knowledge, and make the system smarter with each iteration.
Real-World Impact Across 14 Projects
We applied this workflow across 14 conservation projects in 10 countries, spanning a range of ecosystems, animal groups and goals, showing its broad application.
Scale: Each project processed an average of 875,000 minutes of audio (≈3 TB), targeting around 455 species per region based on GBIF data.
Results: After human validation of AI detections, an average of 178 species were confirmed per project, mostly birds, but also amphibians, mammals, and insects. Notably, an average of 6.3 endangered species per project were identified, based on IUCN classifications. Compared to traditional methods relying on manual inspection of subsets followed by template matching (see our prior work here), this workflow has increased species detection rates by roughly 40%, uncovering a broader and more diverse range of vocal species.
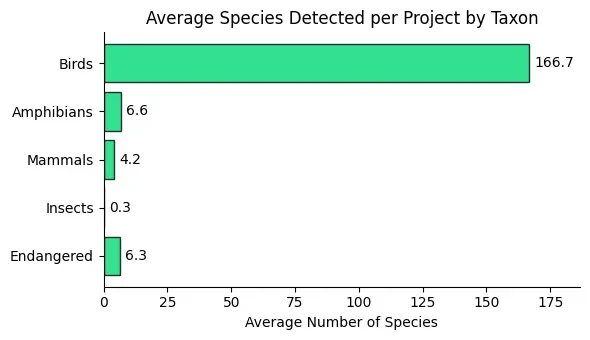
Acoustic monitoring revealed a wide taxonomic range, with birds most common and an average of 6.3 endangered species detected per project.
Efficiency: on average, it took around 2 hours of processing to go from 3 TB of raw audio to species detections ready for validation, showing how scalable and practical this approach can be, even for large datasets.
In Kenya, the acoustic workflow enabled us to analyze hundreds of hours of soundscape data, showing how Forest Garden initiatives, led by farmers working with Trees for the Future and supported by Catona, foster complex habitats, elevate species diversity, and offer a powerful model for integrating biodiversity conservation with food security and local livelihoods.

Local community member deploying an acoustic sensor for biodiversity monitoring in a Forest Garden, Kenya. Source: Trees For The Future’s Instagram page
In the U.S. Virgin Islands, our acoustic pipeline helped the Department of Planning & Natural Resources map the distribution of endemic and threatened species, shaping conservation priorities across the islands. This data was also used by the Southeast Conservation Adaptation Strategy (SECAS) to refine conservation opportunity areas and corridors for the territory in the Blueprint Explorer.
In Brazil, the workflow is being used to provide clear evidence on how forest restoration efforts led by local communities, with support from WeForest and IPÊ, are enhancing habitat complexity and boosting bird diversity across fragmented Atlantic Forest landscapes.

Community-led forest restoration reconnects fragmented Atlantic Forest habitats, boosting biodiversity in Brazil. Photo: WeForest.
In Mexico’s Yucatán Peninsula, Ecosfera and ConMonoMaya members and researchers from Universidad Veracruzana trained a custom model to detect Geoffroy’s spider monkey (Ateles geoffroyi), an endangered species not covered by general classifiers. Starting with only a handful of examples, they used an active learning workflow to run three cycles of validation and retraining. With each iteration, the model uncovered new detections at previously unconfirmed sites, showing how even limited data, when paired with expert validation, can power adaptive and effective species monitoring.

Endangered Geoffroy’s spider monkeys were detected in multiple new sites in the Yucatán Peninsula, Mexico, using just a few initial examples and a custom-trained model.
These examples illustrate how the workflow adapts to different conservation needs, from restoration and planning to species-specific monitoring, enabling partners to generate insights from audio in a matter of hours, not months.
Why This Matters
Most biodiversity monitoring tools aren’t built for scale or for the people on the frontlines of conservation. Our workflow is being designed to change that.
By reusing embeddings, reducing expertise requirements, combining multiple AI models, and enabling collaborative human validation, we’re creating a system that’s fast, powerful, and adaptable across regions and species.
While the workflow is already helping real-world projects today, we're only getting started. The next step is making it open, easy to use, and widely accessible, so that communities everywhere can track biodiversity on their own terms.
Want to Collaborate?
We’re looking for partners, funders, and conservation teams to help us shape the next version of this platform and pilot it in the field.
If you’re interested in bringing this workflow to your project or helping us make it fully open-source, let’s talk.
We’ve proven that this approach works.
Now we want to make it work for everyone.